自动驾驶的发展离不开数据。近日,禾赛科技与Scale AI联合发布了自动驾驶开源数据集 -- PandaSet。PandaSet采用禾赛科技先进的激光雷达进行数据采集,并通过Scale AI强大的标注平台进行精准的数据标注,为从事自动驾驶研发的公司、机构和个人,提供了内容丰富、目标物密集的高质量免费数据。
盘点全球人工智能数据平台,Scale AI是当之无愧的领军者。这家由华裔青年Alexandr Wang在19岁时参与创立的公司,自成立以来一直深受投资者的青睐,仅用3年时间就成为了市值超10亿美元的独角兽企业。依托强大的技术实力,Scale AI结合人工标注、智能工具和标注质量保证体系,推出了面向传感器数据、图像、视频和文本的一系列标注产品,为人工智能应用提供了一流的培训和验证数据。而作为全球,的激光雷达制造商,禾赛科技则凭借自主研发的微振镜和波形加密技术,始终引领传感器创新的发展方向,目前已布局400多项专利,客户遍布全球21个国家和地区的70座城市。此次禾赛科技与Scale AI携手打造PandaSet开源数据集,无疑为自动驾驶行业的发展注入了新的活力。
在自动驾驶的发展进程中,数据是处于核心地位的生产资料,代表着一家公司的核心竞争力,也决定着自动驾驶能否实现安全和稳定。以往,自动驾驶“玩家”对自己的数据普遍呈现出敏感的姿态,而随着自动驾驶的实现难度越来越浮出水面,大家也逐渐认识到单打独斗,不行,开放合作才是正途,于是开源数据集成为了很多自动驾驶公司的选择。
截至目前,Waymo、Cruise、百度、Uber、Lyft、Aptiv等全球,的自动驾驶公司都已陆续开源了自己的数据集,对促进自动驾驶整体研发进程起到了举足轻重的作用。不过,开源数据集并不是自动驾驶公司的“专利”,传感器企业同样有能力在这一领域大显身手,甚至可能比自动驾驶公司做得更好。禾赛科技与Scale AI联合发布PandaSet就是很好的例子,它为自动驾驶行业链条上的很多企业开辟了崭新的发展思路。

PandaSet开源数据集内容概览
PandaSet:疫情期间的一场及时雨
高质量标注数据是训练深度学习算法的“燃料”。目前,全球的自动驾驶公司所使用的深度学习算法,基本都需要使用标注数据来进行训练——只有通过不断学习标注数据,深度学习算法模型才能够帮助自动驾驶汽车更好地识别障碍物。而除了自动驾驶公司,其他自动驾驶算法,,例如学生、学术机构等,同样对高质量标注数据有着持续、强烈的需求。
然而,今年以来,受新冠肺炎疫情冲击,一大批自动驾驶公司不得不暂停路测工作,直接导致可用路测数据的减少甚至断供,对自动驾驶深度学习算法模型的训练造成了严重影响。 在这样的背景下,近日禾赛科技与Scale AI联合发布了PandaSet开源数据集,为众多自动驾驶算法,带来了一场及时雨。
PandaSet数据集采用2款激光雷达和6个摄像头进行数据采集,包含超过16000帧激光雷达点云和超过48000张照片,共100多个场景。除了激光雷达点云和照片外,数据集还包含GPS(全球定位系统)/IMU(惯性传感器)、标定参数、标注、SDK(软件开发工具包)等信息。

PandaSet点云、照片标注对照
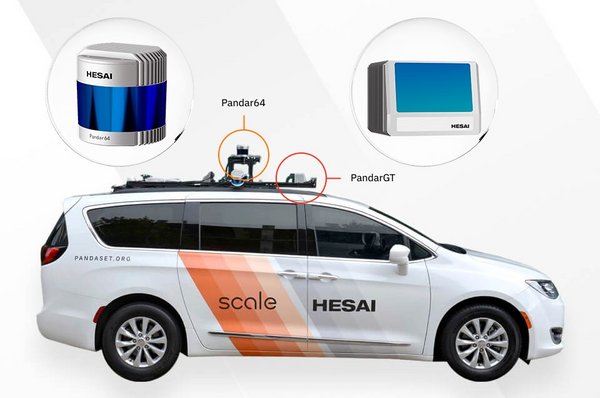
PandaSet数据采集的两款激光雷达Pandar64和PandarGT,以及配置6个摄像头
尤其值得关注的是,PandaSet数据集对100多个场景的每个场景都进行了目标检测,共检测28类物体;大多数场景还进行了语义分割,共37种语义标签。目标检测采用传统的长方体标注,例如,自行车和汽车可以用长方体线框框出来。而对于激光雷达点云数据,并非每个点都隶属于某一目标物,因此数据集还通过点云分割工具精确标注了每个点的语义标签。如此细腻的标注,也为深度学习算法模型提供了,的数据资料。

PandaSet数据集还通过点云分割工具精确标注了每个点的语义标签
对于一个自动驾驶数据集,场景的多样性和复杂性是衡量其优劣程度的重要标准之一。PandaSet数据集中的所有数据均采集自旧金山的城区道路和硅谷的郊区道路,这些道路涵盖了汽车、自行车、交通灯、行人、建筑物等各种各样的交通信息,是对自动驾驶挑战性,的一类应用场景。此外,PandaSet数据集的数据覆盖了白天和黑夜,也让其具备了很强的适用性。

夜晚场景的三维框标注
别被不可靠的数据集带沟里
对于自动驾驶研发者,如果想要训练出优秀的深度学习算法模型,就必须在选择数据集时格外擦亮双眼。因为一些不可靠的数据集,非但不能很好地训练算法,反而会给算法带来巨大危害,起到适得其反的作用。那么,什么样的数据集是不可靠的呢?简单来说,不准确、不完整的数据集就是不可靠的数据集。
一些不准确、不完整的数据集正在把自动驾驶汽车带沟里,其中也包括知名数据集。一个被广泛使用的、包含15000张图片的开源数据集,在该数据集中发现了数千张缺少标注的图片,其中有数百张甚至没有任何标注,但这些图片中确实有小汽车、卡车、自行车、街灯或行人。不仅如此,该数据集还存在虚假标注、复制粘贴的情况,有些标注框的体积明显超标。
“成千上万的学生都在使用开源数据集支持自己的自动驾驶项目,但质量堪忧的数据集极易误导算法模型,从而导致自动驾驶汽车做出糟糕决策,这对于自动驾驶的研发是灾难性的。”
事实上,数据集的准确性和完整性与数据采集、数据标注的流程密切相关。例如,在数据采集中,如果采集车搭载的传感器性能很差,那么采集到的数据质量一定也会很差,直接影响后续的标注及最终的使用。而在数据标注中,如果没有一套完整的标注方法,就很容易出现各种错误标记,如:未标出画面中存在的物体,反而标出不存在的物体,或者标注框没有贴合实际物体,甚至与实际物体发生大幅偏移。
对于如何打造一个高质量数据集,PandaSet是一个优秀案例。在数据采集中,PandaSet用于数据采集的两款激光雷达均为业内,产品,这两款激光雷达由禾赛科技自主研发,、是具有图像级分辨率的前向激光雷达PandarGT,另、是64线机械旋转式激光雷达Pandar64,保证采集到的点云足够准确、清晰、细腻 -- 世界上现有的开源数据集普遍采集较早,还鲜有使用Pandar64和PandarGT这样的高性能激光雷达来采集数据。
此外,在数据标注中,负责该部分的Scale AI作为标注领域的翘楚,具有一套非常严格的标注体系,包括怎么标注、怎么检查、怎么复核、怎么对不合格的标注进行重新标注、怎么管理和考评负责标注的员工等。在整个标注流程中,Scale AI以人工作业为主,结合计算机辅助,充分保证了数据标注的完整性和准确性。
开源数据集是大势所趋
作为自动驾驶行业的领头羊,Waymo也在去年发布了自己的开源数据集Waymo Open Dataset。该数据集包含20万帧画面、1200万条3D标注和120万条2D注释。Waymo希望自家的数据集能够帮助研发者在2D和3D感知、场景理解、行为预测等方面取得进展,从而不断提高自动驾驶汽车的性能,并促进计算机视觉和机器人等其他相关领域的应用。
在Waymo发布开源数据集之前,Cruise、百度、Uber、Aptiv等处于,梯队的自动驾驶公司都已发布了自己的开源数据集。而在Waymo发布开源数据集之后,又有多家公司发布了自动驾驶开源数据集,例如Lyft、福特、奥迪等。
通观自动驾驶开源数据集的发展历程可见,在PandaSet发布之前,开源数据集基本都是自动驾驶公司的“专利”。而禾赛科技的“入局”,则以传感器企业的特殊视角为这一领域添上了一抹亮色,同时也让人们看到了传感器企业在自动驾驶赛场上的更多可能性。
事实上,相比于那些自动驾驶“头部玩家”,传感器企业在开源数据集中的表现并不逊色。以PandaSet为例,该数据集就拥有其他很多数据集没有的优势:采集数据的传感器业内,,采集场景多样化,采集信息密度高,数据标注详尽准确并进行了精细的语义分割。还有非常重要的一点就是,PandaSet面向学术及商业应用均完全开源免费——不像很多开源数据集其实是有商用限制的。不过,PandaSet也有其局限性,例如:总的场景量和数据量均不够大,缺少不同天气状况下的数据,缺少短距激光雷达数据。
当然,PandaSet对于禾赛科技和Scale AI都只是一个开端而已。未来,两家公司将继续深入合作,采用更高线数的激光雷达以及PandarQT等短距激光雷达,采集更多场景、更多数据,并进一步优化标注方法、标注流程,让数据集更丰富、全面,让细节更,。
禾赛科技表示,参与开源数据集是一个非常正确的决定,不仅因为这是同行没做过的事,也因为可以从中取得很多收获。
“一方面,PandaSet数据集为自动驾驶行业丰富了数据,让研发者有更多、更全面、更高质量的数据可以应用和参考,特别是对那些缺少资金和渠道来获取可靠数据集的学生们,帮助巨大。另一方面,数据集也让更多人看到了禾赛激光雷达的表现,有助于吸引客户购买我们的产品。此外,数据采集过程涉及采集车的搭建、不同传感器的融合、多传感器之间的标定……这些都是自动驾驶公司做的事,对禾赛团队是,的考验,也让我们在实践中大大提升了自己的能力。”
就目前而言,开源数据集是大势所趋,是利人利己的一件事。因为自动驾驶数据采集是一个周期长、地域广的超大型项目,如果各家企业都能将自己的数据进行共享,并吸引更多企业和研发者应用并补充数据集,就可以为整个行业大大缩减数据采集时间,从而促进自动驾驶早日实现商业化落地。而从企业自身出发,如果自家的数据或代码被广泛采用,甚至连竞争对手也大量采用,就相当于在业内树立起了一个非正式标准,对企业地位提升和长远发展意义重大。