在投放广告的过程当中,新的广告主可能因为不熟悉程序化广告市场生态和法律,所以在提交的广告素材时,往往在审核的时候被媒体卡住,可能是因为提交的广告素材的质量不达标,或者是也是有意在广告素材中掺入具有刺激性和具有煽动性的内容来达到吸引眼球的目的。
人工的审核往往是耗时耗力的,并且人也是会犯错,同时人也是主观的.然而广告素材的审核往往是对图像音频,或者文本的审核,这正是机器学习最擅长的任务。晓推通过自研的机器学习模型,分别对广告主所提交的图像,视频和文本进行分类,如图1和2所示可以做到政治人物的识别和色情识别。
晓推通过分布式的爬虫抓取各种图片资源来训练自己的深度神经网络,该网络通过海量的图片来训练自己的参数,,到达极高的识别率,如图3所示。

图3.
爬虫的主要技术问题还在于:爬虫系统就是用来爬取数据的,因为系统设计为分布式,因此,爬虫程序本身可以运行在不同的服务器节点上。url调度系统核心在于url仓库,所谓的url仓库其实就是用Redis保存了需要爬取的url列表,并且在我们的url调度器中根据一定的策略来消费其中的url,从这个角度考虑,url仓库其实也是一个url队列。监控报警系统主要是对爬虫节点进行监控,虽然并行执行的爬虫节点中的某一个挂掉了对整体数据爬取本身没有影响,但是我们还是希望知道能够主动接收到节点挂掉的通知,而不是被动地发现。
晓推对广告文本可以识别出非法的具有煽动性的文字,同时新广告法的出台,一些叙述方式和词语也禁止在广告中出现,我们自研的模型也可以识别出这种文本,采用技术是word2vec与CNN的结合,如图4所示。同时我们还利用额外的方法如,形式语言句法和情感极性词典过滤掉相当有部分的文本,以提高速度。
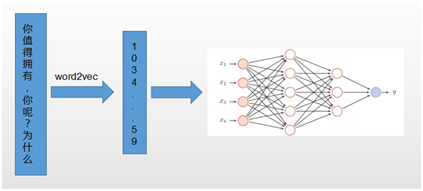
图4. 文本识别模型
作者:晓推技术研发团队