�������գ���˼������ʽ���� TDengine IDMP ��ҵ���ݹ���ƽ̨���汾 1.0.9.0���˴ΰ汾�����۽�ƽ̨����ʹ�ü�ֵ������Ӧ���ݹ�ģ����ģ���������ࡢ�������ݽ������� ��ʹ���Ƿ��临�ӡ� �ĺ��Ĺ��У��Բ���ؼ���������Ϊ����Ŀ��չ�����¡�
���������ݹ�ģ��ʼ����ģ�Ϳ�ʼ��ࡢ��������ʼ�ݽ�ʱ��һЩ����ϸ�ڵ������ͱ����Ҫ�����������絥λ�Ƿ�ͳһ�������ܷ��á���ͼ�Ƿ���Ա��桢�����������ʷ������δ�����
����TDengine IDMP 1.0.6.0�C1.0.9.0 ��һ�εĸ��£�����Χ����Щ��ʹ��ǰ��������չ����������ƽ̨������ǰ�����������ú��������ݽ�ģ��������չ�ͳ�����أ���һ�����ȹ̵Ļ�����
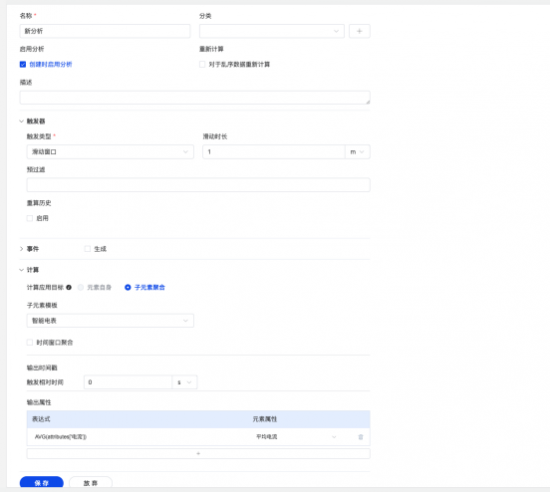
����һ�����ݽ�ģ������һ����������ǿ
����1.Ԫ�ع�ʽ����֧�ֵ�λ�Ƶ�
�������°汾�У�TDengine IDMP ΪԪ�ع�ʽ���������˵�λ�Ƶ�������ϵͳ�����Զ�ʶ��ͬ��Դ������ʹ�õļ�����λ����ѹ����λ psi/bar/MPa��������λ kWh/GJ�������ڼ�����չʾ���������ͳһ���㣬ȷ��ͬһ��ָ��ʼ�ջ���һ�µĶ����ھ�����һ����ʹ�����Բ�ͬ�豸����ͬ�����������ܹ���ģ�Ͳ�ֱ�Ӷ��룬�����������˹������������ҲΪ�糧���Ա�������ؼ����ռ����Լ���������Ч��̼�ŷű����ṩ�˿ɿ������ݻ�����

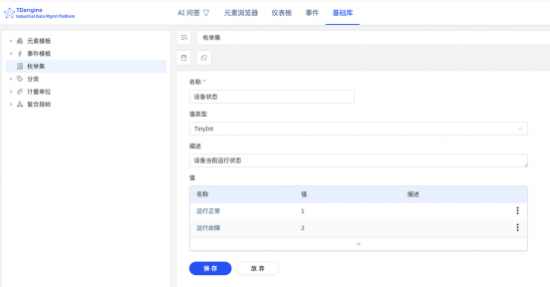
����2.ö�����Ϳ�ӳ�䵽������������
����TDengine IDMP ֧�ֽ�״̬�����͵�ö���б�ӳ�䵽�豸״̬�����Ϸ���������������ԣ�ʹԭ����̬��ö�ٱ����ܹ���ʵ��ҵ�������������ͨ����һ���ƣ�ö��ֵ����ֻ������չʾ��ɸѡ�����ǿ�����Ϊ���������õ�һ���ֲ����������������豸�����ϵ������ݷ�������ʱ����ص�����ģ�͡���������ͱ���Ҳ�ܹ�ͬ����ӳ�仯�������˹�ά���ɱ�����Ϊ�������ʲ���������ά������ҵ����չ�ṩ���ȶ������ݻ�����
�����������ݲ�����ʹ��Ч������
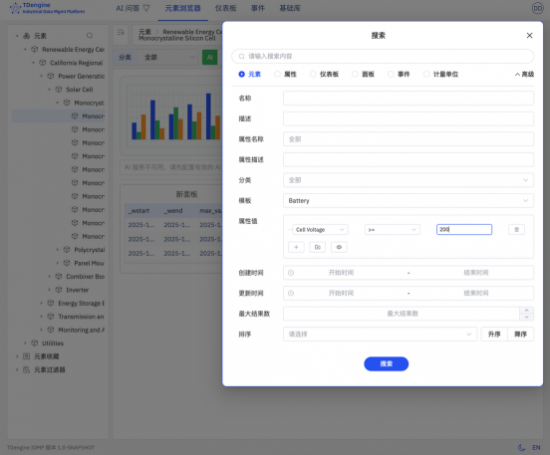
����1.����֧�֣���������
�����ð汾�У�TDengine IDMP Ϊ���������ˣ���������������֧���������д���������£��Զ�����������������ɸѡ��ҵ����Ա����Χ�ƾ������⣬�����趨ɸѡ�������ڴ����豸���������п��ٶ�λĿ���������ݷ�Χ����һ����ʹ��ά��Ա�ܹ�����Ч�ؿ�չ�����Ų�����������ҲΪ������Ա�ڲ�ͬ���������������½��жԱȷ����ṩ�˸�����̽����ʽ��ͬʱ�������ճ�Ѳ�����ع����ж��˹�ɸ��� IT ���õ�������
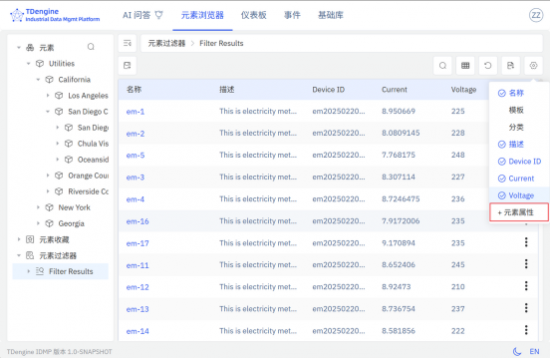
����2.Ԫ���������б�֧�ֱ���Ϊ���
����TDengine IDMP ֧�ֽ����õ������ӽDZ���Ϊ�ɸ��õġ���塱���ڷ������ع����У��û����Խ�ɸѡ�������Ԫ�ؼ���������ϳ�һ��������壬�´�ʹ��ʱ�������ظ����Һ�ѡ��ֱ�Ӽ��ؼ��ɻָ���Ԥ������ݹ�����������һ������Բ�ͬ��ɫ���ճ������й�ע���ݷ�Χ����ϴ��ʵ��������������ڴ�������з������Һ����õIJ����ɱ���ʹ���˳����ӽǡ��Ŷӱ������ͼ�Լ���Ŀ���������ö��ܹ����������ã��Ӷ���������ʹ��Ч�ʲ�����һ����Ա��ʹ���ż���
�����������������Ŀɸ�����ɳ�������
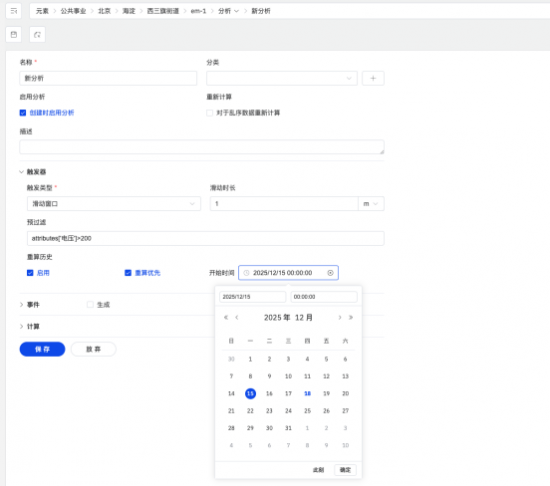
����1.����֧��Ԥ��������ʷ����
����TDengine IDMP �ķ�������֧���ڴ���ǰ�����ݷ�Χ����Ԥ���ˣ����ڷ������������ʷ���ݽ������¼��㡣ͨ��Ԥ���˻��ƣ��������������ض������豸��Χ��ִ�У������ȫ�����ݽ�����Чɨ�裬�Ӷ��������ģ���������µ�ִ��Ч�ʣ�����ʷ����������ʹ���������ģ���ڵ������ܹ���һ�µ�Ӧ�õ�������ʷ�����ϣ���֤��ͬʱ��η�������Ŀɱ�����һ���ԡ���һ���������֧�ַ����ڹ�ģ����ʱ�������ܿɿأ�ҲΪ����������㷨�ij����Ż���������֤�ṩ�˻���������
����2.����ģ��֧����Ԫ��ģ��ۺ�
����TDegine IDMP �ķ���ģ��֧�ֶ���Ԫ��ģ����оۺ����ã�ʹԭ����Ե�ָ�ꡢ��Ԫ�صķ����������Ա���װΪ��һ�������ķ���ģ�壬���Զ�Ӧ�õ�ʹ��ͬһԪ��ģ��Ķ����ϡ�ͨ�����ַ�ʽ�����ӷ������漰�Ķ���������ಽ�账���Ͷ�����жϿ��Ա�ͳһ�̻�Ϊ��ģ�壬������ͬ���豸���з����ֹ����á���һ���������ڽ�����֤��Ч�ķ�������ר�Ҿ�����б������������ڲ�ͬ�豸����Ŀ���������ã�Ϊ���ӷ����Ĺ�ģ������ͳ��������ṩ������
����������ʽ��
����• �ڴ�������ģ��ʱ���ڡ����㡱�ġ�����Ӧ��ģ�塱ѡ����Ԫ�ؾۺϡ�
����• ѡ��һ����Ԫ��ģ��
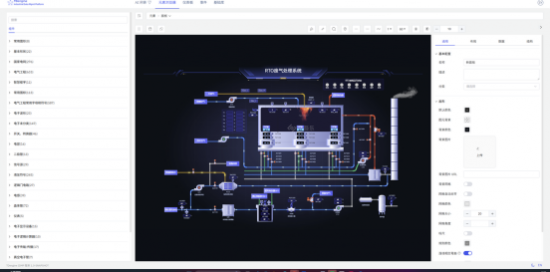
�����ġ�����ҵ���Ŀ��ӻ���ϵͳ��������
����1.���֧�֣���̬����
��������ʹ�ó����ĸ��ӻ�����ҵ�����ڲ�ͬ��ɫ������Ҫ�Բ�ͬ��ʽ�������ʹ�ã���һ�������б�������֧����ά��غ������ߡ�TDengine IDMP �������������룬��̬�����������û������ݽ�һ����̬Ϊ��ؿ��塢��������ͼ��ҵ���档ͨ����ͬһ��ʵʱ����֮�Ϲ���������ͼ���û����趨�ƿ������ɿ����γ�������ȡ��豸������Ӫ�����Ȳ�ͬ������Ӧ�ý��棬ʵ�� ��һ�����ݡ�������ͼ��N ��Ӧ�á���ʹ�ؼ���Ϣ�ܹ��ڸ����ʵ��龳�г��֣������쳣��ӦЧ�������ȷ�ԣ�Ҳ��ǿ��ҵ����Ա�����ݼ�ֵ��ֱ�۸�֪��
����2.AI �Ƽ��������ɶ���쳣������
����TDengine IDMP ֧�� AI �Ƽ�һ�����ɶ���쳣���ָ����������⣬�û�ͨ���ļ���������Ϳ������ɶ���쳣����ӷ��������������Խ����ӵ��쳣���������̽���ģ�黯��⣬��������ϴ��������ȡ�Ͷ�ģ���жϵȲ������Ϊ�ֲ㼶�����ܷ�������ͨ�����ַ�ʽ���������پ����ڵ�һ��ֵ�����ǿ�����ͬһ�������������ۺ϶�ά���������жϣ��Ӷ�ʶ������Ρ����Ӹ��ӵ��쳣ģʽ��ͬʱ����߷���������ȶ��ԺͿ��Ŷȣ�Ҳʹ��ط��������ܹ���ģ����ʽ�����ã����ͣ�������ʵ�ʳ����е����ú�ʹ���ż���
����3.������̨��������д��˵�
����TDengine IDMP �ڹ�����̨������������д������������֧��ͨ�� MQTT��Kafka ����Ϣ���жԶ�������Դ����ʵʱ���������롣ͨ�����л��Ľ����������ͬ��Դ���豸���ݡ���������˹�¼����Ϣ����ͳһ��۵�ͬһƽ̨�����ڽ�������б���ʱ���ϵ���������һ���ԡ���һ���Ƽ����������粨����ɼ��쳣��ɵ�����ȱʧ�ʹ��ң�Ҳʹ�߱�Ȩ��ҵ����Ա�ܹ�����ά�����ݽ������ã��Ӷ����Ͷ� IT ������������������ݽ�������ά������ԡ�
����4.�����¼��SSO��
����TDengine IDMP ֧������ҵ���е�ͳһ������֤��ϵ���ɣ��ṩ�����¼������ʹ�û������һ��������֤�ɰ�ȫ����ƽ̨�������ظ���¼���ڶ�ϵͳ�������еĹ�ҵ�����У���һ���ƿ��Խ� TDengine IDMP ���˺���Ȩ����������ҵͳһ������������ϵ��ȷ���˺Ŵ�����Ȩ�ޱ������ְע����������̱���һ�¡�ͨ��������֯�ṹ���û���ļ�����Ȩ���������˷��ʿ��Ƶ�ȷ�ԣ�Ҳ�����˶����˺���ϵ�����Ĺ����ɱ���ͬʱ���û��ڿ�ϵͳʹ�ù����л�ø���������˳���IJ������顣
��������
�����ӹ��ܲ��濴��1.0.6.0�C1.0.9.0 �ĸ��¸����˽�ģ�����������ӻ���ϵͳ���ɵȶ�����棻����ʹ�ýǶȿ������Ǹ������ڰ�һЩ����������������⡱��ǰ���������λ�Ƶ���������ӳ�䣬����������ݹ�ģ�����ھ�����ʧ�ص����⣻����ģ�塢Ԥ��������ʷ���㣬������Ƿ�����һ�����������ά�������⣻�������̬���������ú�����ͬ��ɫʹ��ͬһ�����ݳ�Ϊ���ܡ���Щ���������������š��������Ǿ����� TDengine IDMP �ں��������ҵ���ݹ�����������ʱ���Ƿ���ҪƵ���Ʒ�������











