柏睿实时云数仓性能优化篇来也!本文分享实战经验。前情可前往历史文章回顾~
RapidsDB在云端的整体优化,可以概括为计算、存柏睿分布式内存数据库储、网络三个方面,我们在这里分别做一些介绍。
再次强调我们优化的整体思路:虽然云计算号称“按需付费”,但如果不精打细算,使用成本反而会增加很多。因此我们在优化柏睿实时云数仓的主要思路是:在成本可控的情况下,通过优化相关的云资源,提升柏睿分布式内存数据库的性能。
一、计算如何优化?
在第二篇“根据CPU选云主机”中已介绍过如何选择CPU和云主机类型,对于“团队作战”的RapidsDB集群,单纯提升CPU 一点点频率效果不会很明显。
将数据库集群规模扩大,将任务分配到更多的数据库节点,这才是提升性能的最直接而有效的方法。由于是团队作战,所以要求所有数据库节点CPU和内存配置是统一的,以方便统一调度管理。
CPU与内存的配置比率,我们在“选择内存容量”中已介绍过,推荐1:4或1:8。但在数据库中还是需要一些优化设置的。
RapidsDB是一个高度可扩展的分布式系统,运行在Linux 系统中。在每个数据库节点,通过本节点的数据分区技术,实现多任务并行操作。例如在一个8vCPU的数据库云主机节点,数据的分区数据量为8。
,再对操作系统做一些常规的优化,如打开文件数量等。由于一些云厂商会调整优化Linux内核,因此不建议调整云主机的内核。
下图是不同规模的实时云数仓集群,在TPC-H 500G的测试数据量性能报表,能看到整体计算性能随着节点数量的增加而提升。

二、存储如何优化?
在“选择云硬盘”中已介绍过如何选择硬盘,对于“团队作战”的RapidsDB集群,单纯提升云主机一点点IO能力,性能提升效果不会很明显。
将数据库的存储设置为独立磁盘,避免与其他程序同时读写同一磁盘,这将会大幅度提升数据库的存储能力。
如果在云中运行的RapidsDB所在的业务有很频繁的磁盘性能要求,可以通过在云主机中增加多块云硬盘,组成RAID 0,实现更高的读写性能。对于为什么不做RAID 5,可以参考柏睿实时云数仓的安全文章。
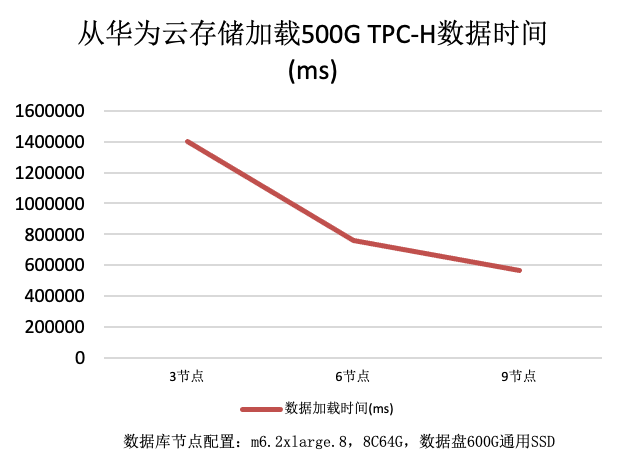
下图是不同规模的实时云数仓集群,从华为云存储加载数据的时间,能看到随着节点数量的增加,文件加载性能也有提升。
三、网络如何优化?
在“选择网络能力”中已介绍过如何选择网络,很多人认为云主机在内网通讯的速度会很快,但在实际测试过程中,我们还发现一个隐含的小问题:
云厂商在不同物理位置有区域,在每个区域中又有不同的可用区。比如华为云在北京四区有4个可用区。
虽然在北京四这个区域中,每个可用区之间的网络通信都是内网,但跨可用区网络通信时,网络延时会增加。下面是通过ping不同可用区之间的延时比较:
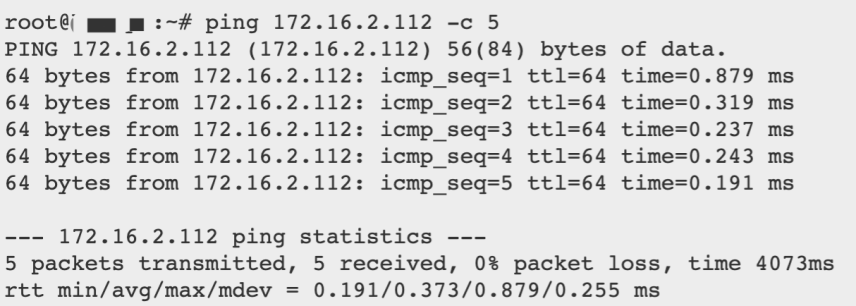
PING本可用区云主机延时
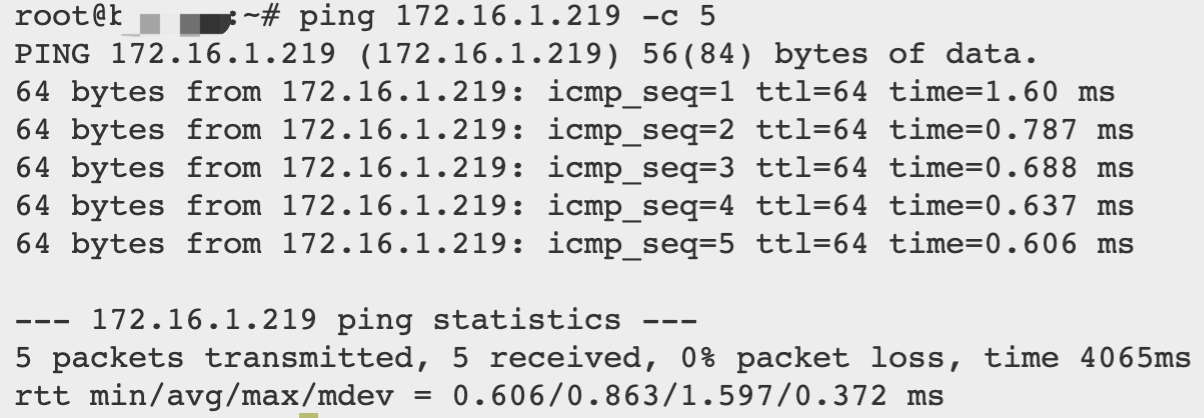
PING其他可用区云主机延时
从上面PING的测试数据能看到,跨可用区的网络访问对于柏睿云数仓这种分布式数据库来说,还是有网络影响的。如果需要高性能,还是将所有数据库节点部署在同一可用区,如果出于数据安全考虑,可以参考原柏睿实时云数仓的安全文章,使用数据多副本并将数据库节点部署在不同可用区。
,,虽然在云计算环境中不建议调整网络帧大小,但可以对一些常规网络参数调整,如调整重试次数、FIN完成时间等。
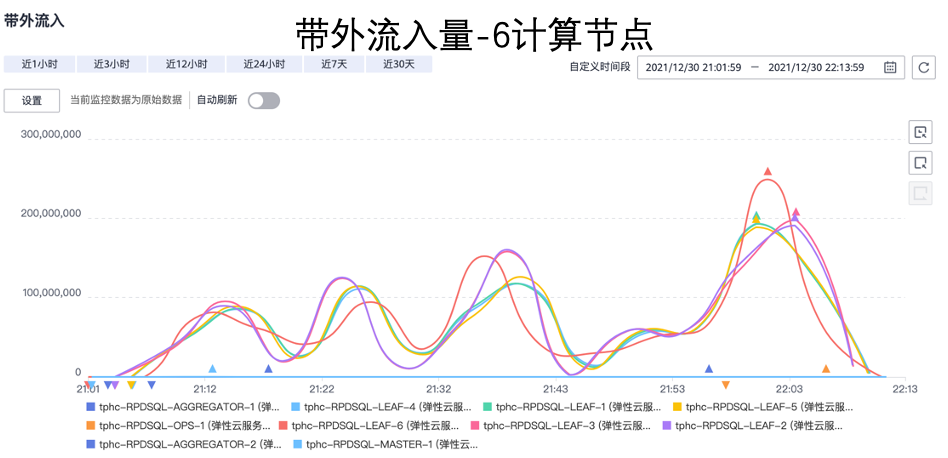
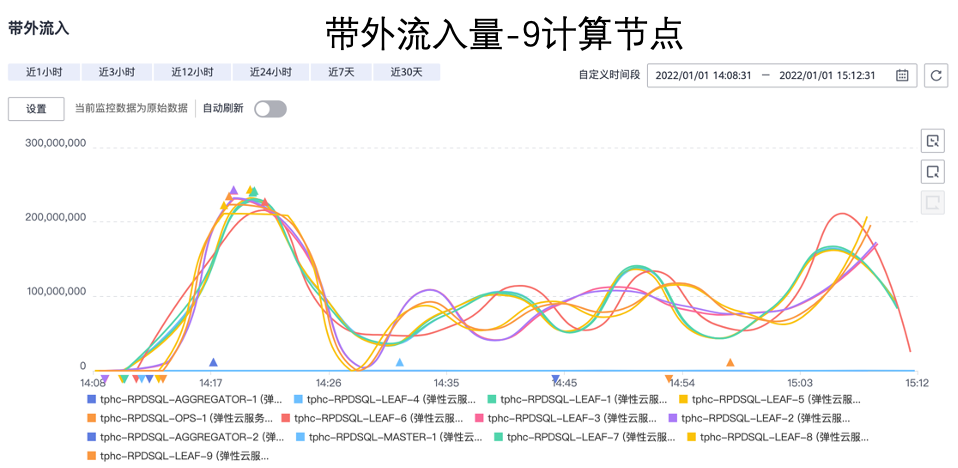
下图是不同规模的实时云数仓集群,网络流量性能报表,能看到随着节点数量的增加,网络性能也有提升。
四、成本如何优化?
由于是团队作战,所以要求所有数据库节点配置是统一的,以方便统一调度管理。
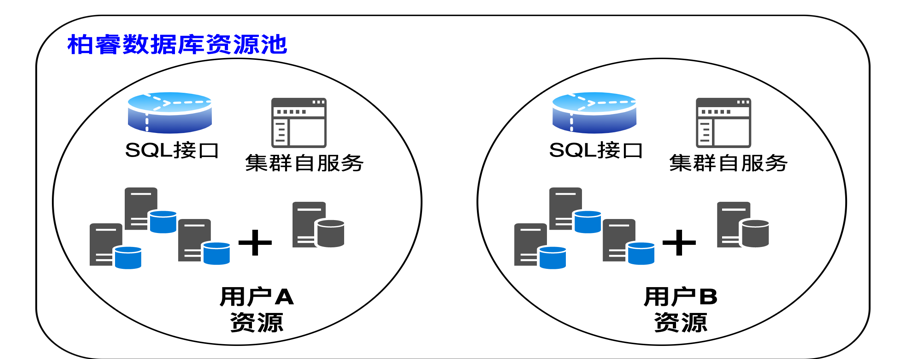
随着集群规模的扩大,使用成本也会扩大。基于RapidsDB的实时云数仓,使用云原生微服务架构,支持在线弹性增加、删除数据库节点,用户在处理大型任务时弹性增加数据库集群规模,在不需要高性能计算时可以减少数据库集群规模,以实现云成本的优化。
守正出奇
,,引用冯仑的自著《野蛮生长》中对“守正出奇”的修改:
“守正出奇”,“正”正路、正道,“奇”出人意料,“守正出奇”正道而行。突破思维、出奇制胜。就是用百分之七十的时间去想“正确”的优化方向,用百分之三十的时间研究运行环境与业务需求的变通。既不墨守成规,又有创新。











